Productionizing a Broadband Churn Model
A public-safe MLOps pipeline that turns synthetic broadband customer data into validated scores, action routing, API predictions, monitoring reports, and a dashboard.
GitHub repo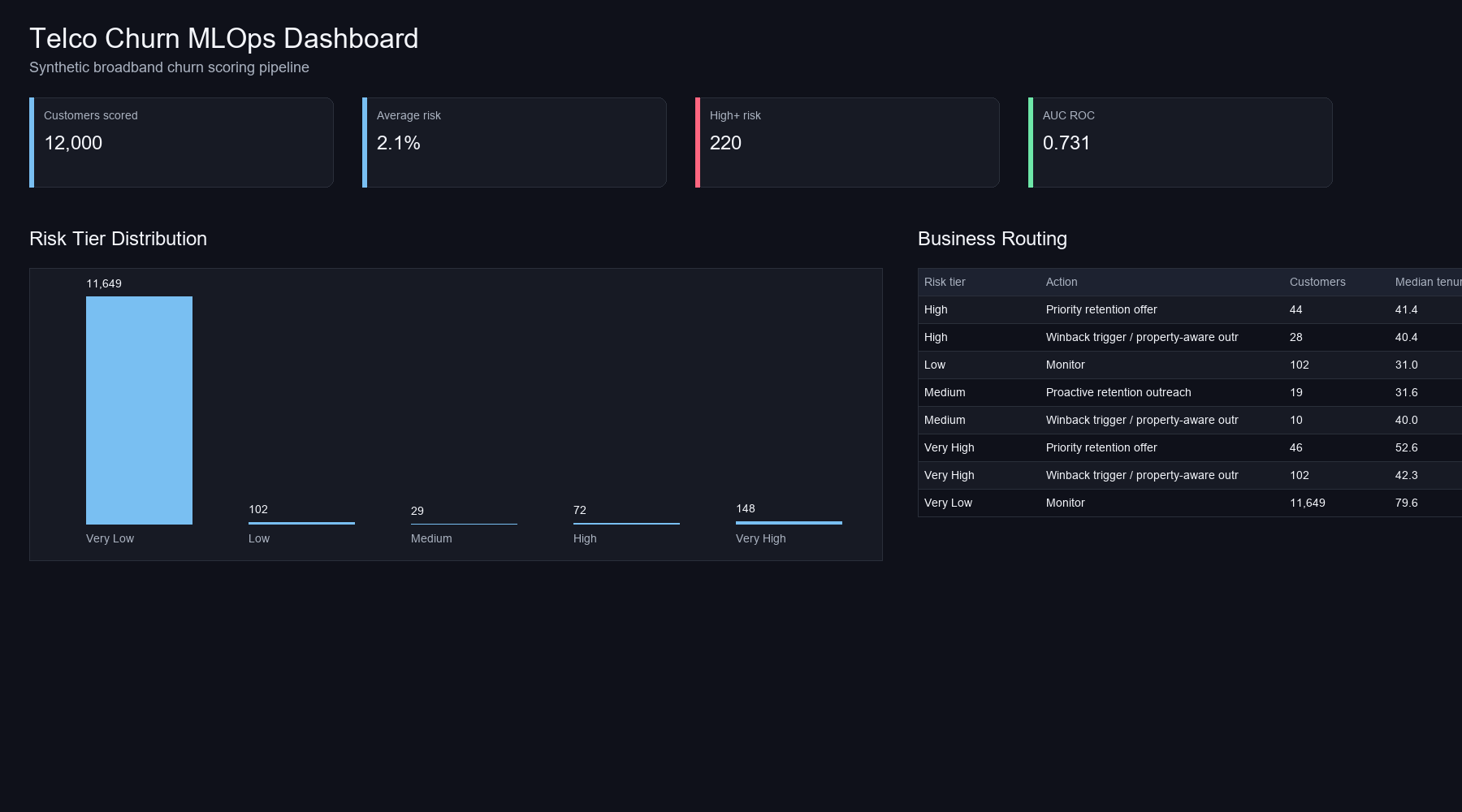
Problem
A one-time churn score is useful once. A churn pipeline is useful repeatedly. For a broadband operator, the valuable workflow is not just predicting which customers are likely to leave. It is being able to refresh the score, route each customer to a business action, monitor whether the model is drifting, and explain the output to people who need to act on it.
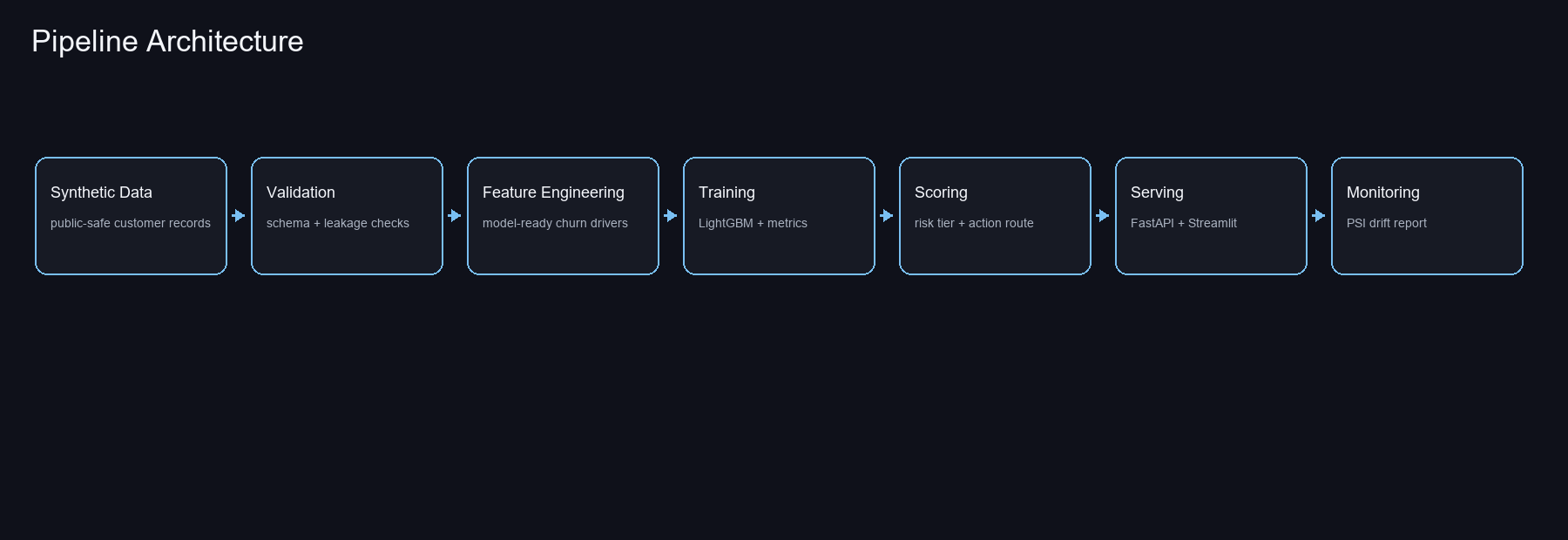
Pipeline
The project starts with synthetic telco-like customer records. Each customer has realistic churn drivers such as tenure, ARPU, bundle depth, autopay, address turnover, competitive area, and MDU or rental-proxy flags. The data is synthetic so the project can be public while still reflecting realistic broadband churn patterns.
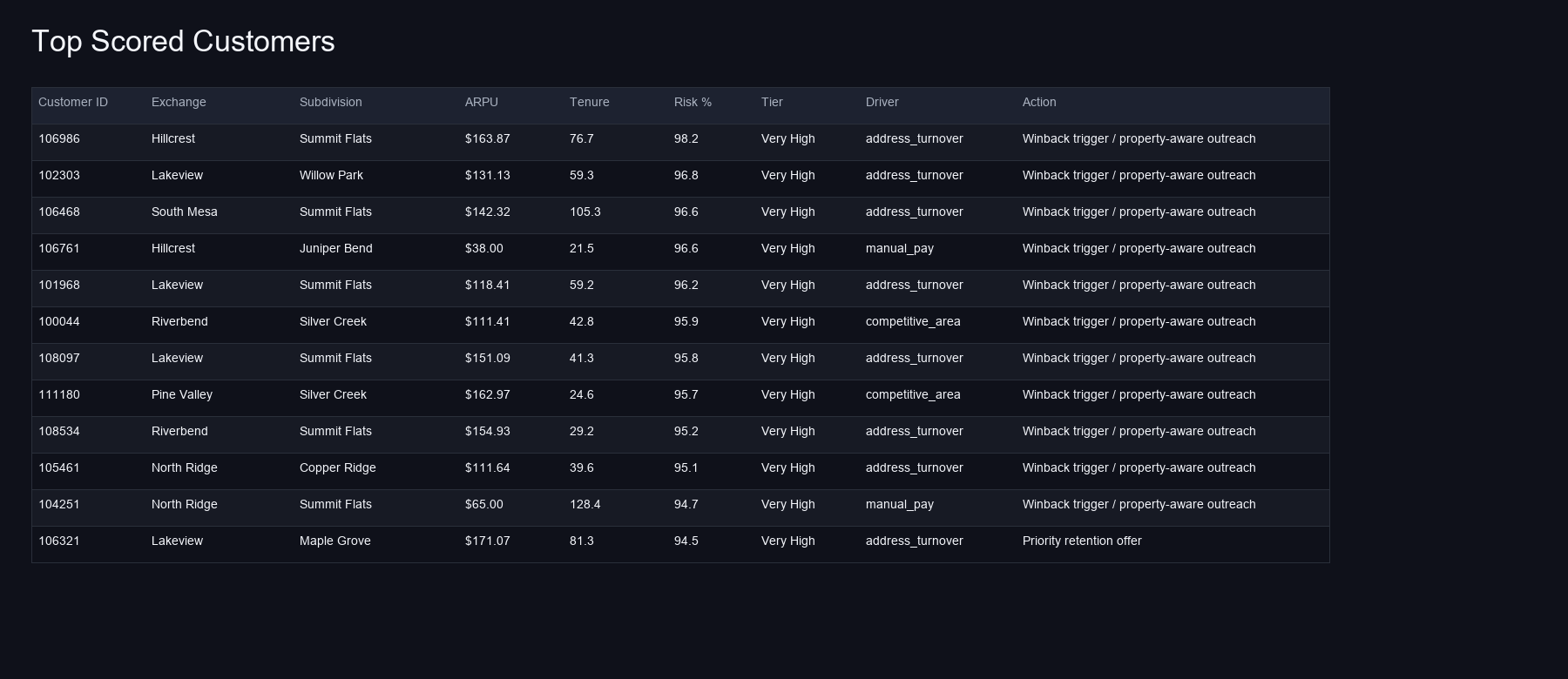
Business Routing
The score answers who is likely to churn. The routing layer answers what kind of action makes sense. Stable-address customers with medium or high risk are routed toward retention outreach. Rental-proxy or MDU customers are routed toward winback or property-aware outreach because their risk may be driven by address lifecycle rather than dissatisfaction.
MLOps Surface Area
- Data generation, validation, model training, scoring, monitoring, API, dashboard, and tests.
- Schema, range, and leakage checks before training.
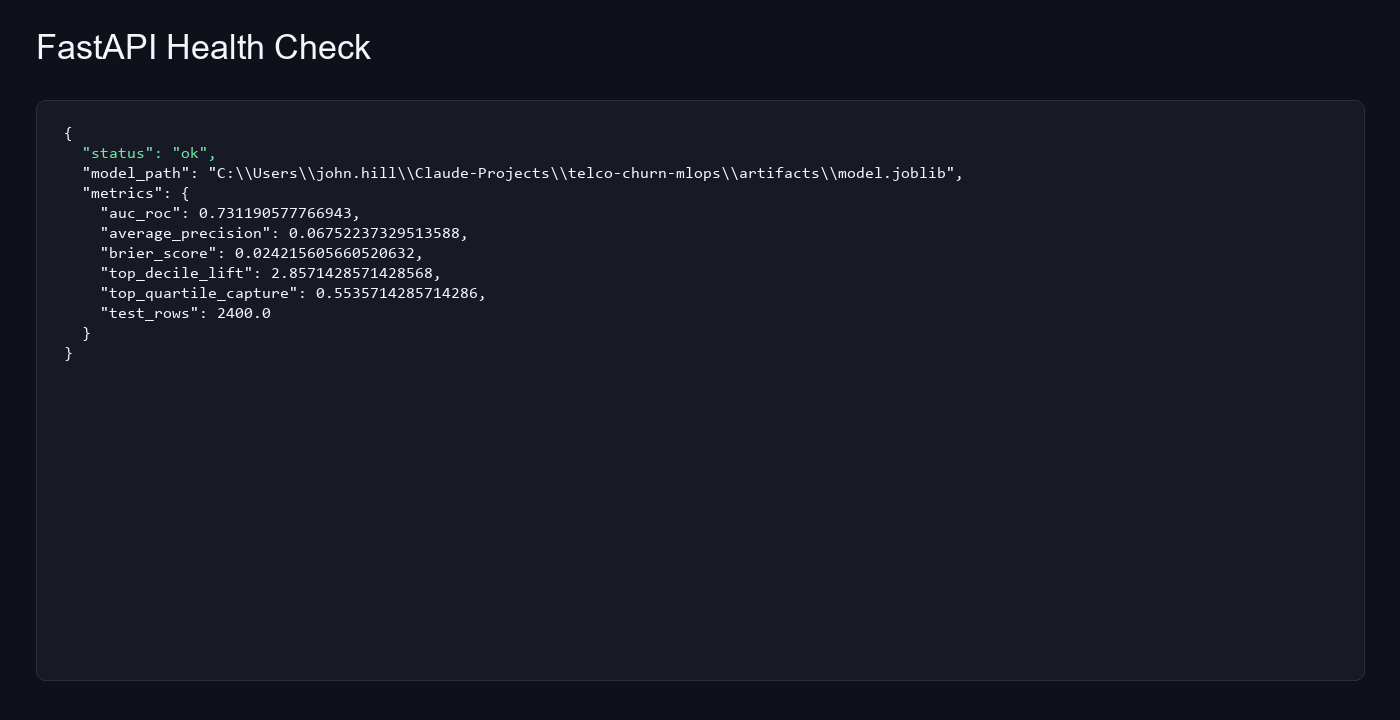
- LightGBM model metrics plus local artifact output.
- FastAPI health, single prediction, and batch prediction endpoints.
- GitHub Actions CI on every push and pull request.
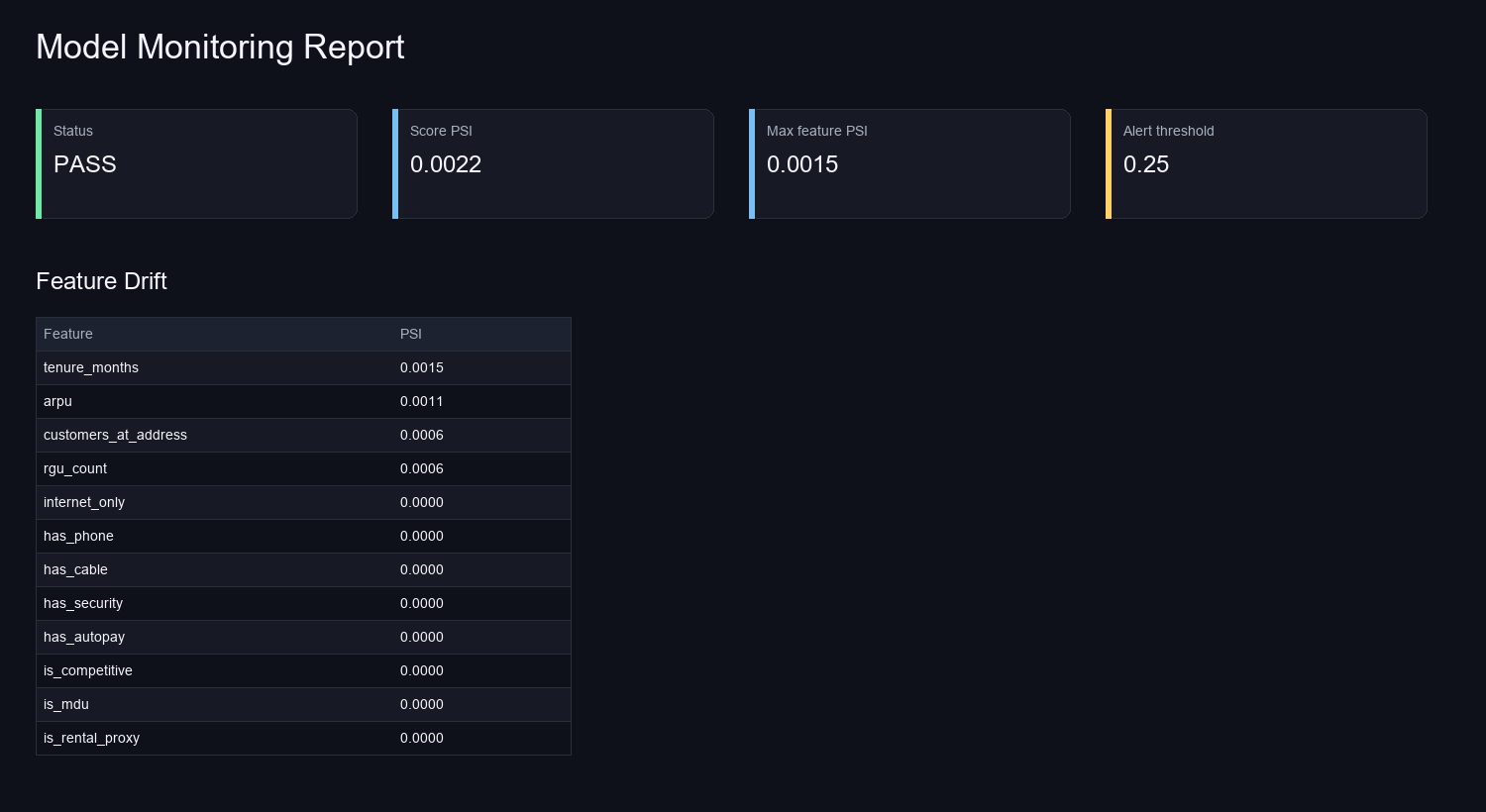
Lesson
A model is only one layer of an operational system. Validation, leakage prevention, reproducible scoring, monitoring, and business routing are what make the model usable after the first presentation. This is the kind of AI-assisted analytics work I want to keep doing: analysis that lands as a repeatable system, not a one-off artifact.